
发布日期:2024-08-04 12:55 点击次数:101
股鑫宝[[441262]]
人们观察场景通常是观察场景中的物体和物体之间的关系。比如我们经常这样描述一个场景:桌面上有一台笔记本电脑,笔记本电脑的右边是一个手机。
但这种观察方式对深度学习模型来说很难实现,因为这些模型不了解每个对象之间的关系。如果不了解这些关系,功能型机器人就很难完成它们的任务,例如一个厨房机器人将很难执行这样的命令:「拿起炒锅左侧的水果刀并将其放在砧板上」。
为了解决这个问题,在一篇 NeurIPS 2021 Spotlight 论文中,来自 MIT 的研究者开发了一种可以理解场景中对象之间潜在关系的模型。该模型一次表征一种个体关系,然后结合这些表征来描述整个场景,使得模型能够从文本描述中生成更准确的图像。

论文地址:https://arxiv.org/abs/2111.09297
现实生活中人们并不是靠坐标定位物体,而是依赖于物体之间的相对位置关系。这项研究的成果将应用于工业机器人必须执行复杂的多步骤操作任务的情况,例如在仓库中堆叠物品、组装电器。此外,该研究还有助于让机器能够像人类一样从环境中学习并与之交互。
每次表征一个关系该研究提出使用 Energy-Based 模型将个体关系表征和分解为非规一化密度。关系场景描述被表征为关系中的独立概率分布,每个个体关系指定一个单独的图像上的概率分布。这样的组合方法可以建模多个关系之间的交互。
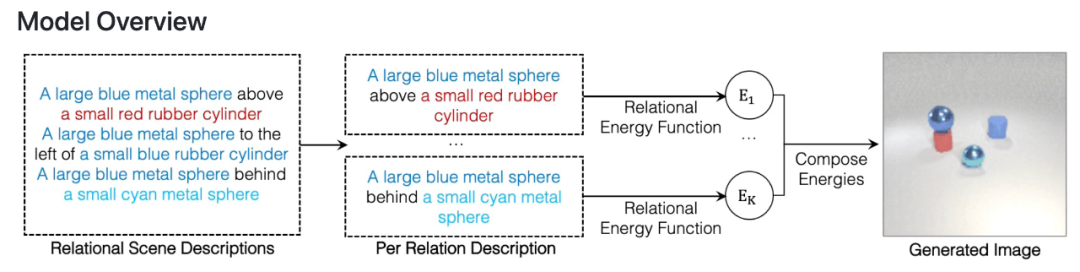
该研究表明所提框架能够可靠地捕获和生成带有多个组合关系的图像,并且能够推断潜在的关系场景描述,并且能够稳健地理解语义上等效的关系场景描述。
在泛化方面,该方法可以推广到以前未见过的关系描述上,包括对象和描述来自训练期间未见过的数据集。这种泛化对于通用人工智能系统适应周围世界的无限变化至关重要。
以往的一些系统可能会从整体上获取所有关系,并从描述中一次性生成图像。然而这些模型不能真正适应添加更多关系的图像。相比之下,该研究的方法将单独的、较小的模型组合在一起,能够对更多的关系进行建模并适应新的关系组合。
此外,该系统还可以反向工作——给定一张图像,它可以找到与场景中对象之间的关系相匹配的文本描述。该模型还可通过重新排列场景中的对象来编辑图像,使它们与新的描述相匹配。

研究人员将他们的模型与几种类似深度学习方法进行了比较,实验表明在每种情况下,他们的模型都优于基线。
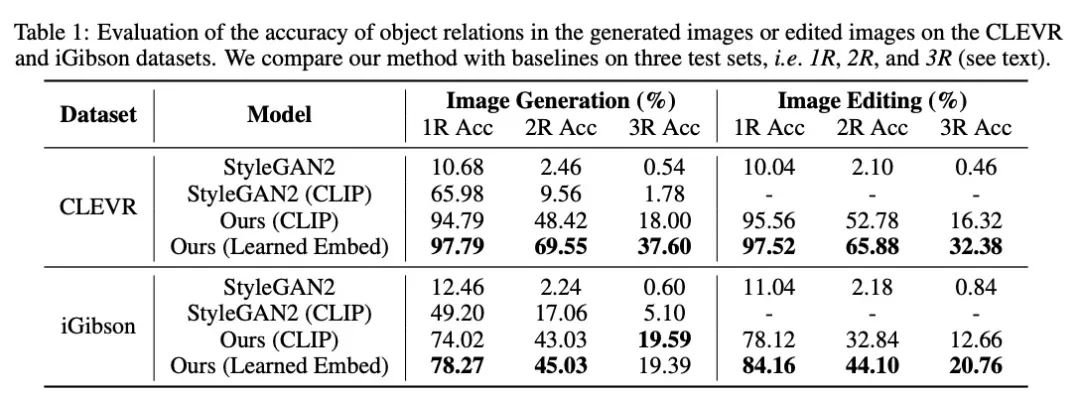
他们还邀请人们评估生成的图像是否与原始场景描述匹配。在描述包含三个关系的示例中,91% 的参与者认为该模型的性能比以往模型更好。
这些早期结果令人鼓舞,研究人员希望未来该模型能够在更复杂的真实世界图像上运行,这需要解决物体遮挡、场景混乱等问题。
他们也期待模型最终能够整合到机器人系统中,使机器人能够推断现实世界中的物体关系,更好地完成交互任务。
感兴趣的读者可以阅读论文原文了解更多研究细节。